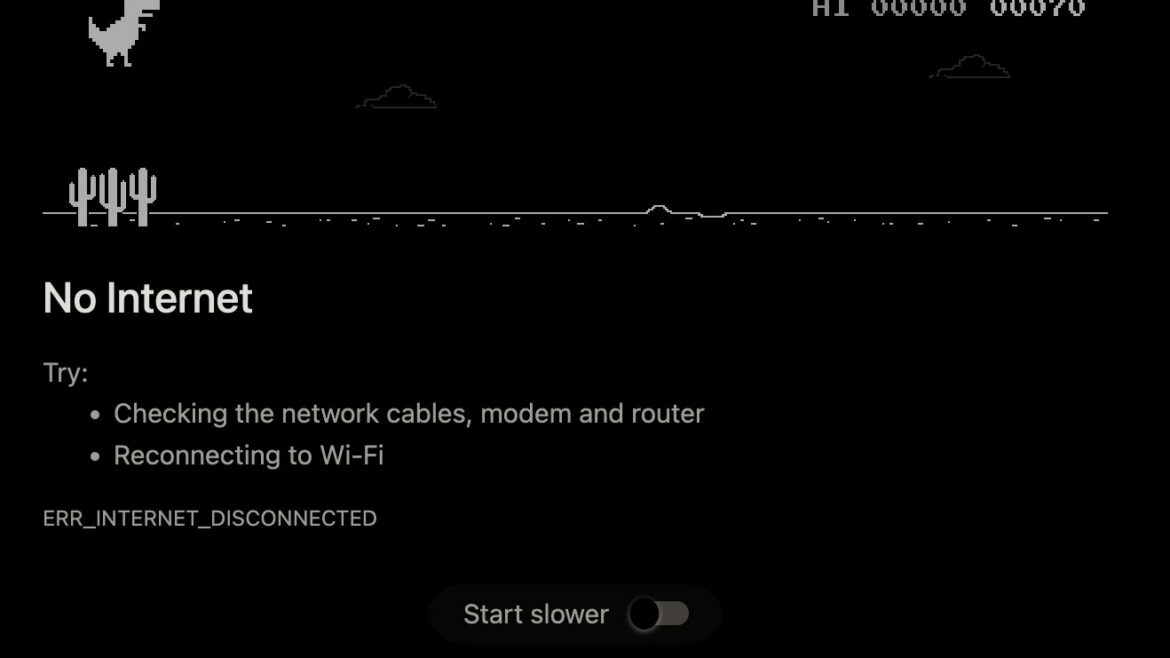
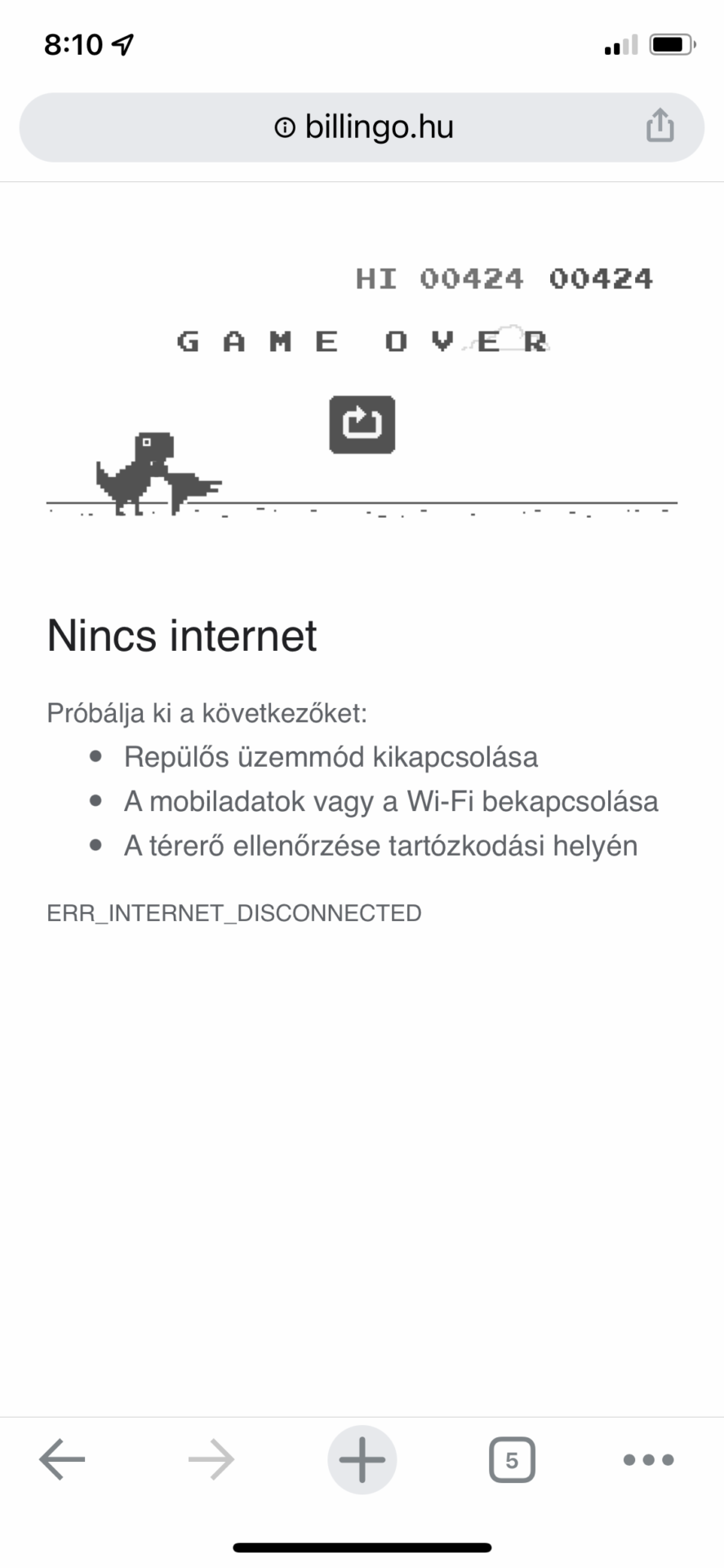
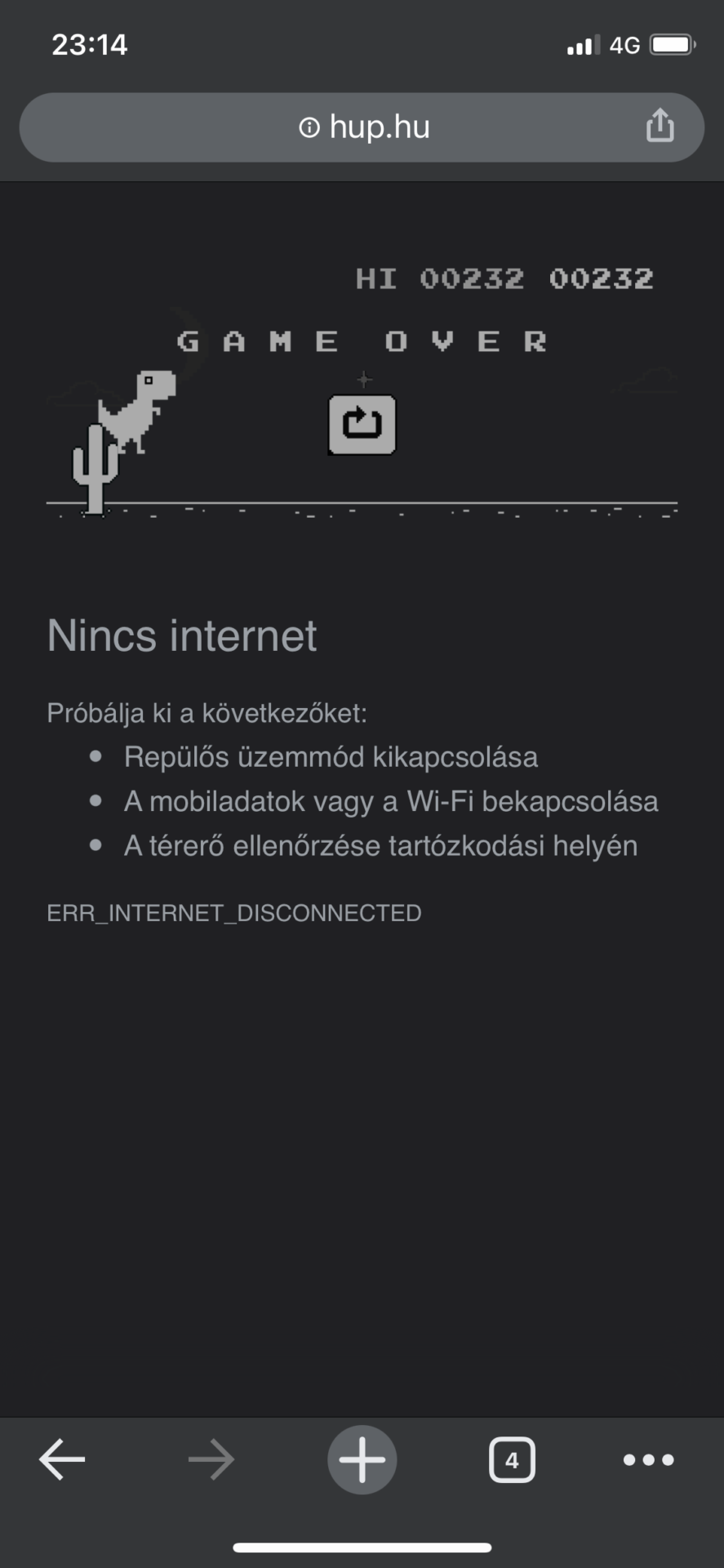
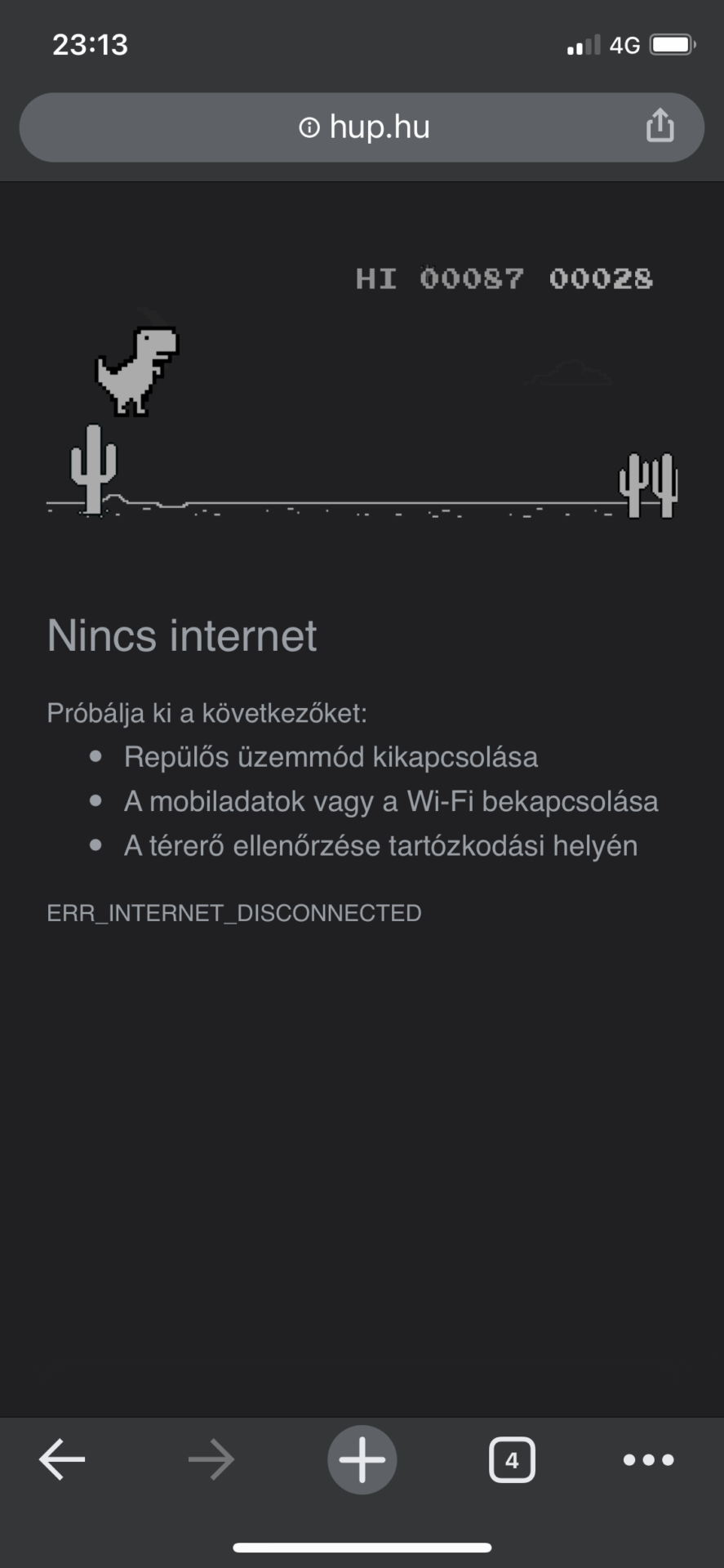
Yesterday, while reading hup.hu, the internet goes off and the usual dinosaur appeared, I think everyone knows it.
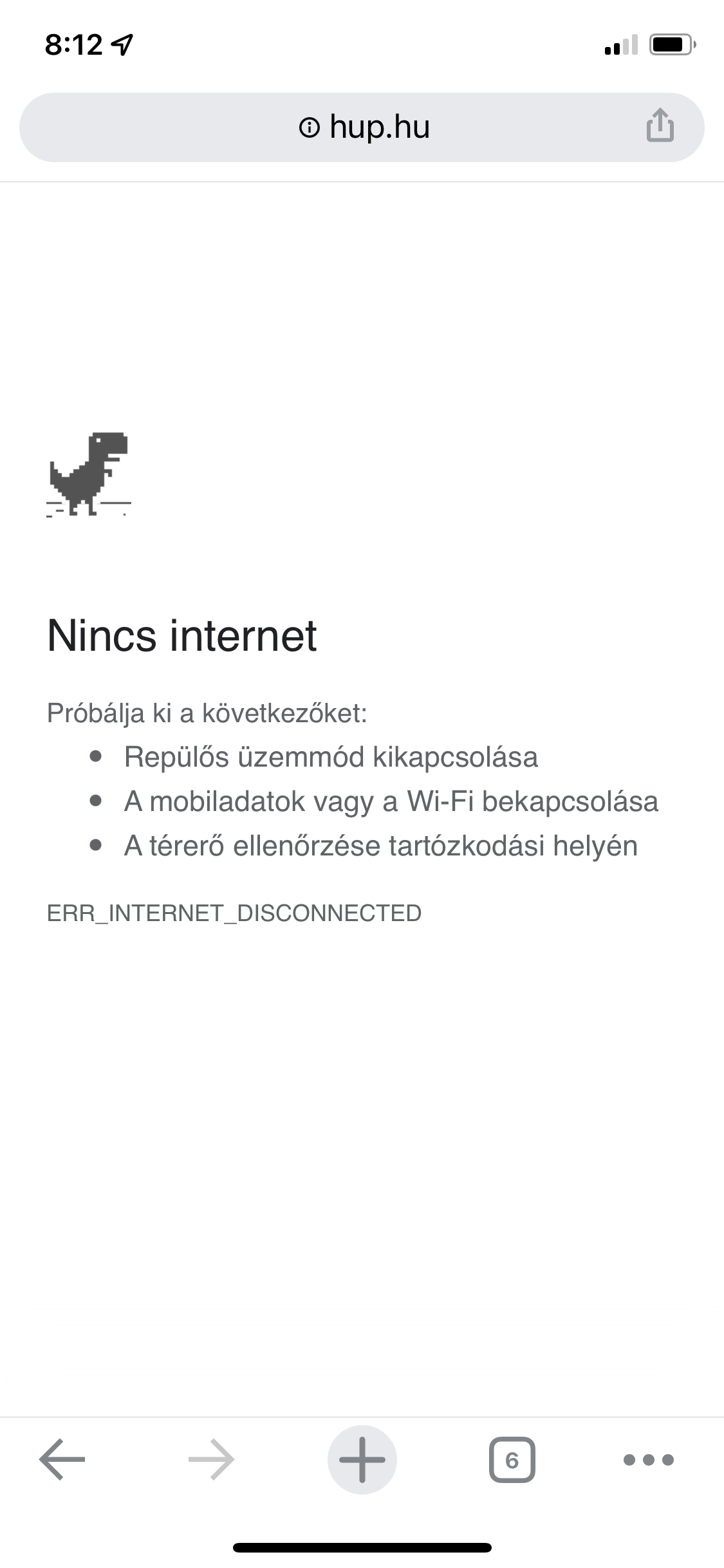
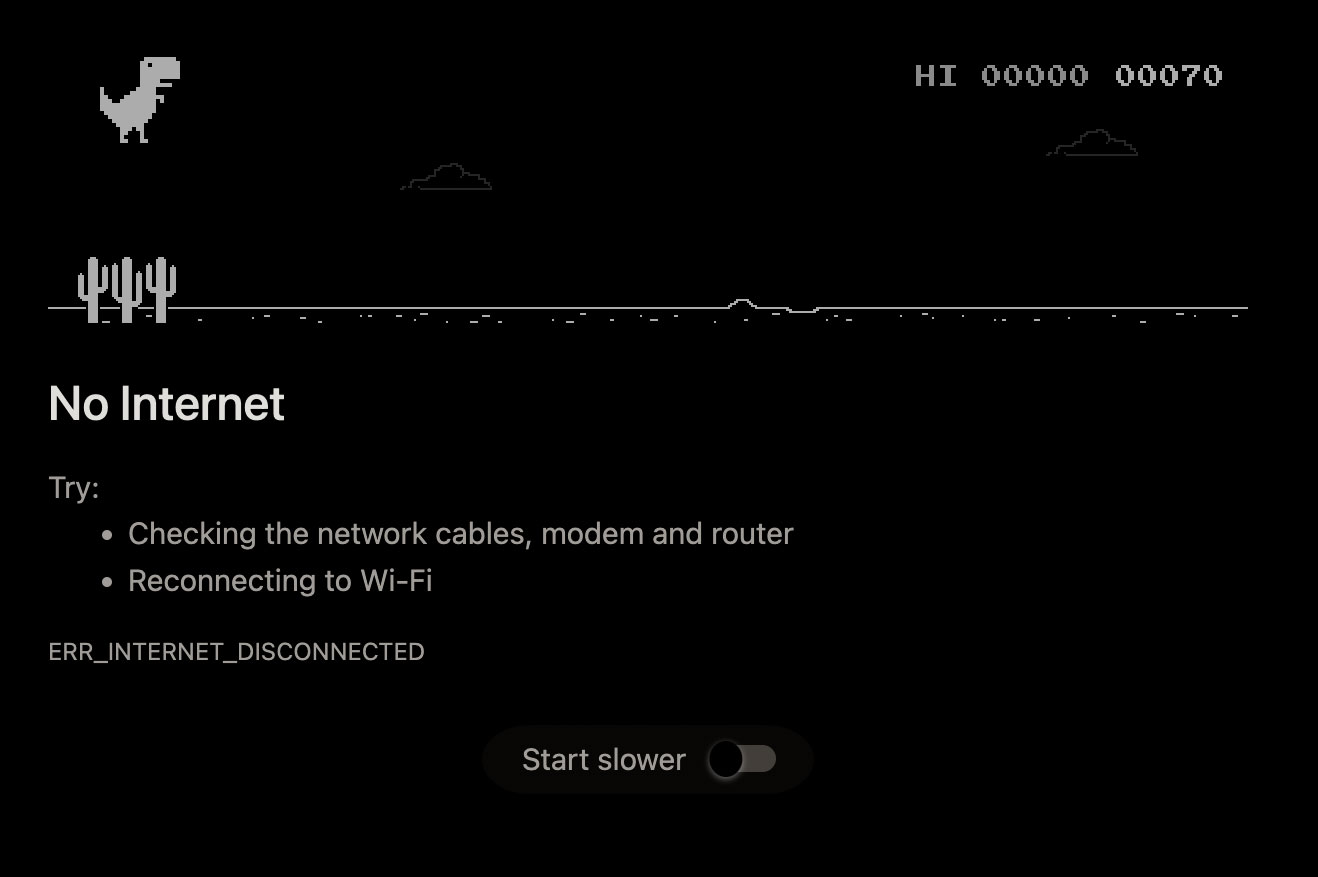
I accidentally clicked on the dino and suddenly it started. It’s not complicated, the dino goes to the edge of the screen by itself and you can jump with it, which you have to avoid the different obstacles. There is also a normal and a darkmode. After a while, birds also come, obviously if the dino attacks the cactus or the bird, it’s game over. I don’t know who was the programmer who created this, but I welcome you here too, I really enjoyed it 🙂
I looked it up and on the one hand it also works on desktop Chrome (there is also a sound and a speed adjustment option), in addition there is a dedicated command, you just have to type this into the Chrome browser bar:
chrome://dino/
Maybe someone else already knew this, but all jokes are new to a newborn 😀










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}